
Многопоточность и асинхронность на языке C#
Всем привет! Я являюсь бэкенд-разработчиком на WPF и ASP.NET. Сегодня я расскажу про многопоточность и асинхронность на языке C#.
Что вы узнаете из этой статьи? План такой:
— Разберемся, что такое многопоточность. Разберем 3 задачи:
— Разберемся, что такое Mutex и Semaphore
— Я поделюсь тремя примерами best practices
Давайте начнем с того, что такое многопоточность.
Многопоточность - это свойство платформы, состоящее в том, что процесс, порожденный операционной системой, может состоять из нескольких потоков, выполняющихся “параллельно”. При выполнении некоторых задач такое разделение может достичь более эффективного использования ресурсов вычислительной машины.
Об этом как раз и будет наша первая задача.
У нас есть три метода: Task1, Task2 и Task3. На выполнение каждого из них требуется определенное время. Первый выполняется 3 секунды, второй - 1 секунду, третий - 2 секунды. Условно это могут быть какие-то запросы в базу данных, либо на сторонний сервис, после чего возвращается результат. Здесь он сильно упрощенный, в виде простого числа. Мы должны посчитать сумму этих результатов и вывести на консоль.
Что вы узнаете из этой статьи? План такой:
— Разберемся, что такое многопоточность. Разберем 3 задачи:
- Многопоточное выполнение кода
- Асинхронное выполнение кода
- Синхронизация и dead lock
— Разберемся, что такое Mutex и Semaphore
— Я поделюсь тремя примерами best practices
Давайте начнем с того, что такое многопоточность.
Многопоточность - это свойство платформы, состоящее в том, что процесс, порожденный операционной системой, может состоять из нескольких потоков, выполняющихся “параллельно”. При выполнении некоторых задач такое разделение может достичь более эффективного использования ресурсов вычислительной машины.
Об этом как раз и будет наша первая задача.
У нас есть три метода: Task1, Task2 и Task3. На выполнение каждого из них требуется определенное время. Первый выполняется 3 секунды, второй - 1 секунду, третий - 2 секунды. Условно это могут быть какие-то запросы в базу данных, либо на сторонний сервис, после чего возвращается результат. Здесь он сильно упрощенный, в виде простого числа. Мы должны посчитать сумму этих результатов и вывести на консоль.

Если мы будем выполнять код в том виде, в котором он сейчас есть, последовательно вызывая каждый метод, то он будет выполняться 6 секунд, и результат получится 12.

Соответственно, эти три задачи можно распараллелить, потому что у них нет каких-то входных данных, которые бы зависели друг от друга.

Как это можно сделать с использованием тредов? Вот код, где мы создадим новые треды, после этого их запустим и подождем их завершения.

Соответственно, время выполнения занимает три секунды, результат 12. Все правильно посчиталось.

Но у этого кода есть ряд проблем:

- много технического кода (выглядит неприятно)
- нет использования пула потоков. Пул потоков - это такой набор потоков, которые уже готовы к работе.
Само по себе создание нового треда - это достаточно дорогостоящая операция, поэтому подобного нужно избегать.
Давайте реализуем первую задачу с использованием ThreadPool.

Кода стало еще больше. И теперь у нас появились дополнительные сущности. Задача будет решена также: мы получим время чуть больше трех секунд и результат 12.

Какие есть проблемы у этого кода?
- Во-первых, нам нужно использовать ManualResetEvent. ManualResetEvent - это объект, который дождется завершения выполнения асинхронных операций, которые были запущены в другом потоке
- Из-за этого у нас неявно устанавливается значение task1Result, task2Result task3Result . Их можно использовать преждевременно, до того как мы дождемся завершения работы этих потоков, что может привести к неявным ошибкам.
- Технического кода стало еще больше

Теперь давайте реализуем ту же самую задачу с использованием Task.
Для того, чтобы создавать многопоточность в C#, существуют класс Thread и класс Task.
Для того, чтобы создавать многопоточность в C#, существуют класс Thread и класс Task.

Код стал сильно проще. Также получаем результат 12 и общее время выполнения чуть больше 3 секунд.

Но и у этого кода также есть небольшая проблема. Проблема здесь в том, что Task1, Task2 и Task3 запускаются в отдельных потоках, и эти потоки блокируются, потому что внутри них используется метод ThreadSleep. ThreadSleep является блокирующим. Итого, у нас запустится три потока, каждый из них на какое-то время заблокируется, и они будут просто ничего не делать. Так как у нас в системе ограниченное количество потоков, то это не очень хорошо, и здесь нам нужно использовать асинхронность.

Вторая задача у нас будет как раз об асинхронности. После её решения мы вернемся обратно к первой и доделаем ее.
Вторая задача.
Вторая задача.

Нам нужно выполнить метод Sum, который посчитает сумму от единицы до n, где в виде n передается миллион. Если мы выполним этот код синхронно, то он отработает достаточно быстро, и мы получим результат.

Но задача в том, что мы должны выполнить это асинхронно. Сделаем это через делегаты.

Это устаревший код. На .Net7 этот код вообще не компилируется.
Собственно, что в этом коде написано? Мы запускаем выполнение делегата и передаем ему значение 1000000, которое будет передано в метод Sum, а также передаем метод EndSum, который будет вызываться по завершению Асинхронной операции. Таким образом у нас произойдет разрыв при выполнении этого кода. Метод EndSum будет вызван после завершения асинхронной операции.
Итого мы запустили асинхронную операцию, остановили stopwatch и вывели на консоль TotalTime. Как только сумма будет подсчитана, выведется результат.
Сначала мы получим TotalTime, a потом Result, что показывает, что код запустился асинхронно.
Собственно, что в этом коде написано? Мы запускаем выполнение делегата и передаем ему значение 1000000, которое будет передано в метод Sum, а также передаем метод EndSum, который будет вызываться по завершению Асинхронной операции. Таким образом у нас произойдет разрыв при выполнении этого кода. Метод EndSum будет вызван после завершения асинхронной операции.
Итого мы запустили асинхронную операцию, остановили stopwatch и вывели на консоль TotalTime. Как только сумма будет подсчитана, выведется результат.
Сначала мы получим TotalTime, a потом Result, что показывает, что код запустился асинхронно.

Какие проблемы у этого кода?
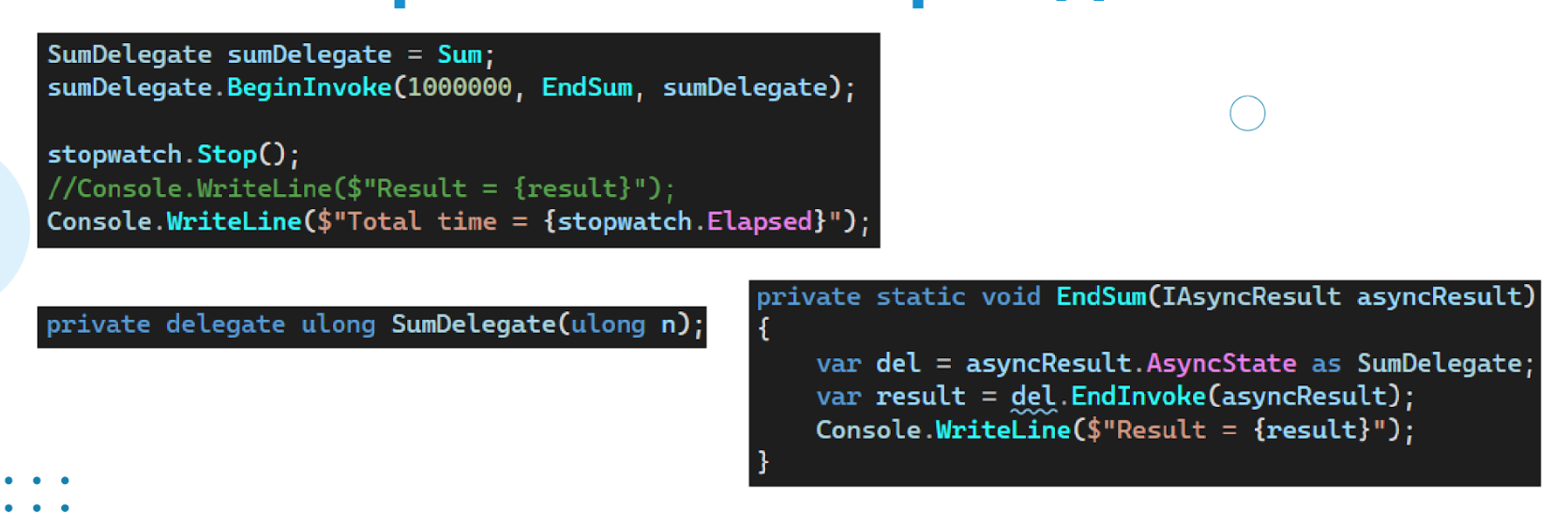
Одна из проблем в том, что нам сложно захватывать переменные при разрыве.
Если у нас перед вызовом метода Sum есть какие-то переменные, значения, данные, которые нам нужно использовать после разрыва, то, для того чтобы протащить их в EndSum, нам нужно написать дополнительный код и еще больше усложнять и без того сложный код.
Теперь давайте реализуем эту задачу с использованием класса Task.
Если у нас перед вызовом метода Sum есть какие-то переменные, значения, данные, которые нам нужно использовать после разрыва, то, для того чтобы протащить их в EndSum, нам нужно написать дополнительный код и еще больше усложнять и без того сложный код.
Теперь давайте реализуем эту задачу с использованием класса Task.

Мы вызовем метод Task.Run и используем оператор await. Оператор await скрывает разрыв от нас, и мы видим код, будто бы он просто синхронный. Хотя на самом деле здесь будет тот разрыв, который я привел ранее. Итого, оператор await дождется завершения выполнения асинхронной операции, и сначала мы увидим результат Result, а после этого уже увидим TotalTime. Как видите, все сработало отлично.

При использовании оператора Await нам нужно использовать ConfigureAwait(false).В ConfigureAwait можно передать true или false, разница будет в том, в каком потоке продолжится выполнение кода после разрыва. Как я сказал, оператор await создаёт разрыв, который от нас скрыт, и код, который будет вызван после завершения асинхронной операции, может выполняться в разных потоках.
ConfigureAwait(false) говорит о том, что выполнение кода после разрыва может продолжиться любым свободным потоком. Такой вариант предпочтительнее так как системе не нужно дожидаться, когда освободится конкретный поток.
В таких ситуациях, когда код написан на технологии WPF или WinForms, есть проблема, что с элементами окна может работать только UI поток. И в случае, если мы переключим контекст через ConfigureAwait(false), то код выдаст исключение при обращении к каким-то элементам на форме после разрыва.
И также приведу пример о том, что переменные теперь захватывать очень легко. Весь тот код, который будет протаскивать переменную X, от нас скрыт. И мы даже не увидим, что это может создать какую-то сложность, мы просто создали X до await, и после await его легко используем. Все легко и просто.
ConfigureAwait(false) говорит о том, что выполнение кода после разрыва может продолжиться любым свободным потоком. Такой вариант предпочтительнее так как системе не нужно дожидаться, когда освободится конкретный поток.
В таких ситуациях, когда код написан на технологии WPF или WinForms, есть проблема, что с элементами окна может работать только UI поток. И в случае, если мы переключим контекст через ConfigureAwait(false), то код выдаст исключение при обращении к каким-то элементам на форме после разрыва.
И также приведу пример о том, что переменные теперь захватывать очень легко. Весь тот код, который будет протаскивать переменную X, от нас скрыт. И мы даже не увидим, что это может создать какую-то сложность, мы просто создали X до await, и после await его легко используем. Все легко и просто.

И давайте вернемся к первой задаче.

Перепишем наш метод Task1. Я его не удалял, а написал еще один метод Task1WithDelay.
Для того, чтобы сделать паузу в C#, существуют два метода: первый - это Thread.Sleep, который использовался ранее, а второй - это Task.Delay. Разница между ними в том, что Task.Delay является асинхронным, и на него можно применить оператор await. Соответственно, написав такой код, мы также получаем результат 12 и время чуть больше 3 секунд, и это будет правильное решение первой задачи.
Для того, чтобы сделать паузу в C#, существуют два метода: первый - это Thread.Sleep, который использовался ранее, а второй - это Task.Delay. Разница между ними в том, что Task.Delay является асинхронным, и на него можно применить оператор await. Соответственно, написав такой код, мы также получаем результат 12 и время чуть больше 3 секунд, и это будет правильное решение первой задачи.

Перейдем к третьей задаче, которая касается синхронизации и deadlock.
Задача заключается в том, что у нас есть поле `Count` в классе `Counter`, и нам нужно инкрементировать его по миллиону раз в пяти разных потоках.
Задача заключается в том, что у нас есть поле `Count` в классе `Counter`, и нам нужно инкрементировать его по миллиону раз в пяти разных потоках.

Итого `Count` должен равняться пяти миллионам. Если мы выполним код в том виде, в котором он сейчас есть, то мы получим очень неоднозначные результаты.

Проблема заключается в том, что операция инкремента не является атомарной. Она выполняется так: сначала считывается значение из оперативной памяти, перегоняется в кэш процессора, там инкрементируется, а потом записывается обратно в оперативную память.
Как это будет работать для поля `Count`? Допустим, в поле было записано число 5. Два потока одновременно высчитали число 5, в процессоре их инкрементировали до 6 и записали обратно 6. Итого, по факту было две инкрементации, но поле изменилось с 5 до 6.
Результаты могут варьироваться в зависимости от количества ядер процессора на вашем компьютере. Если бы у вас был процессор однопоточный, то вы бы всегда получали 5 миллионов. Сейчас, наверное, таких компьютеров уже ни у кого нет.
Реализуем эту задачу с синхронизацией.
Как это будет работать для поля `Count`? Допустим, в поле было записано число 5. Два потока одновременно высчитали число 5, в процессоре их инкрементировали до 6 и записали обратно 6. Итого, по факту было две инкрементации, но поле изменилось с 5 до 6.
Результаты могут варьироваться в зависимости от количества ядер процессора на вашем компьютере. Если бы у вас был процессор однопоточный, то вы бы всегда получали 5 миллионов. Сейчас, наверное, таких компьютеров уже ни у кого нет.
Реализуем эту задачу с синхронизацией.

Первый вариант синхронизации - это класс `Interlocked`. Он представляет набор методов, которые атомарно меняют значения интовых переменных.
Один из методов Interlocked - это метод `Increment`, в который можно передать ref Count, и он инкрементирует его значение на единицу. И это уже будет потокобезопасно.
Если выполнить код, то получаем нужные 5 миллионов. В этом случае немного увеличился TotalTime, потому что даже при таком варианте у нас есть синхронизация, что тратит процессорное время.
Один из методов Interlocked - это метод `Increment`, в который можно передать ref Count, и он инкрементирует его значение на единицу. И это уже будет потокобезопасно.
Если выполнить код, то получаем нужные 5 миллионов. В этом случае немного увеличился TotalTime, потому что даже при таком варианте у нас есть синхронизация, что тратит процессорное время.


Реализация третьей задачи с помощью класса `Monitor`.

`Monitor` имеет два метода: `Enter` и `Exit`. В эти методы нужно передать любой референс-объект. Суть его заключается в том, что если один из потоков вызвал `Monitor.Enter`, на, допустим, typeof(Program), то второй поток, попытавшийся это сделать, встанет на паузу до тех пор, пока тот поток, который уже взял лок, не вызовет `Monitor.Exit`. Таким образом, код будет выполняться только одним потоком в один момент времени. Здесь также произойдет синхронизация, но время выполнения заметно увеличится. Мы также получаем 5 миллионов.

Реализация третьей задачи с использованием lock

За счет того, что Monitor.Enter и Monitor.Exit - достаточно частые операции, в языке C# было сделано специальное слово `lock`, и эти две секции абсолютно эквивалентны друг другу. `lock` развернется до `Monitor.Enter` и `Monitor.Exit`, где `Monitor.Exit` выполняется вне зависимости от того, будет исключение или нет в блоке `lock`.
Поговорим о том, на что можно ставить `lock`.
Первый вариант - можно ставить на typeof от любого типа, например, если мы находимся в статическом классе `Program`.
Второй вариант - это объект, с которым будет происходить работа в блоке. Например, если у нас есть класс `Point`, в котором есть два свойства, и мы хотим потокобезопасно изменить какое-нибудь из них, мы можем взять `lock` на этот `Point` и внутри этого блока как-либо манипулировать объектом.
И третий вариант, самый предпочтительный, это создавать приватные поля и на них брать `lock`.
Поговорим о том, на что можно ставить `lock`.
Первый вариант - можно ставить на typeof от любого типа, например, если мы находимся в статическом классе `Program`.
Второй вариант - это объект, с которым будет происходить работа в блоке. Например, если у нас есть класс `Point`, в котором есть два свойства, и мы хотим потокобезопасно изменить какое-нибудь из них, мы можем взять `lock` на этот `Point` и внутри этого блока как-либо манипулировать объектом.
И третий вариант, самый предпочтительный, это создавать приватные поля и на них брать `lock`.

Поговорим о проблеме `deadlock`

Допустим, у нас есть два метода: `ChangePoint1` и `ChangePoint2`. Один сначала берет `lock` на `Point1`, а потом на `Point2`. А `ChangePoint2` сначала берет `lock` на `Point2`, а потом на `Point1`. Возникает ситуация, когда они будут бесконечно ждать друг друга, пока кто-то из них не разблокирует соответствующий `Point`. Это проблема, которую стоит избегать."

Давайте поговорим о том, почему первый и второй пункт установки лока плохие, и по большей степени всегда стоит использовать именно третий вариант.
Если мы будем брать lock на Point, как это сделано в предыдущем примере, то внутри этого Point кто-то может взять lock на этот же Point с помощью lock(this). Стоит избегать подобного, потому что ide (среда разработки) вам об этом не подскажет. Это выяснится только на этапе запуска, а также это может быть плавающей ошибкой. По той же причине брать lock на тип не стоит. Поэтому всегда стоит создавать приватное поле и использовать его.
Если мы будем брать lock на Point, как это сделано в предыдущем примере, то внутри этого Point кто-то может взять lock на этот же Point с помощью lock(this). Стоит избегать подобного, потому что ide (среда разработки) вам об этом не подскажет. Это выяснится только на этапе запуска, а также это может быть плавающей ошибкой. По той же причине брать lock на тип не стоит. Поэтому всегда стоит создавать приватное поле и использовать его.

Что такое Mutex?
Сейчас мы говорили о классе Monitor, в котором есть методы Enter и Exit. Они работают внутри одной программы и одного процесса.
Mutex - это объект, который позволяет поставить межпроцессную блокировку.
Допустим, у вас может быть одновременно запущено три разных программы, одна из них поставит Mutex на какой-то объект, и две другие программы это увидят.
Сейчас мы говорили о классе Monitor, в котором есть методы Enter и Exit. Они работают внутри одной программы и одного процесса.
Mutex - это объект, который позволяет поставить межпроцессную блокировку.
Допустим, у вас может быть одновременно запущено три разных программы, одна из них поставит Mutex на какой-то объект, и две другие программы это увидят.

Дальше у нас идет класс Semaphore.
Класс Semaphore позволяет зайти в критическую секцию нескольким потокам. В его конструкторе задается count, говорящий о том, сколько потоков одновременно могут выполнять критическую секцию. На использование Mutex и Semaphore дальше будут примеры, я думаю, будет понятно, когда их нужно применять.
Best Practices.
Первый метод, который я часто использую, вызывается на какой-либо асинхронный метод, тогда, когда нам не нужно дожидаться его завершения. То есть мы должны запустить операцию и пойти дальше выполнять следующий код. Нюанс в том, что код будет выполняться синхронно до первого реального await, который вызовет разрыв.
Класс Semaphore позволяет зайти в критическую секцию нескольким потокам. В его конструкторе задается count, говорящий о том, сколько потоков одновременно могут выполнять критическую секцию. На использование Mutex и Semaphore дальше будут примеры, я думаю, будет понятно, когда их нужно применять.
Best Practices.
Первый метод, который я часто использую, вызывается на какой-либо асинхронный метод, тогда, когда нам не нужно дожидаться его завершения. То есть мы должны запустить операцию и пойти дальше выполнять следующий код. Нюанс в том, что код будет выполняться синхронно до первого реального await, который вызовет разрыв.

Давайте разберем такую ситуацию.
Method1 делает асинхронную паузу на 2 секунды.
Method2 делает сначала синхронную паузу на одну секунду, а потом делает асинхронную паузу на две секунды.
В методе Main первый WriteLine со стартом напишет текст в консоль в нулевую секунду, дальше мы заходим в Method1.
Так как мы вызвали его через FireAndForgetSafeAsync, как только код уйдет в асинхронное выполнение, мы вернемся обратно в Main.
Method1 делает асинхронную паузу на 2 секунды.
Method2 делает сначала синхронную паузу на одну секунду, а потом делает асинхронную паузу на две секунды.
В методе Main первый WriteLine со стартом напишет текст в консоль в нулевую секунду, дальше мы заходим в Method1.
Так как мы вызвали его через FireAndForgetSafeAsync, как только код уйдет в асинхронное выполнение, мы вернемся обратно в Main.

Когда мы заходим в Method2, сначала у нас идет синхронная пауза на 1 секунду, далее печатается Method2 is running. И после этого делается асинхронная пауза на две секунды, но мы возвращаемся к продолжению выполнения Main.
Итого, Method2 будет выполняться 1 секунду. И после этого мы получим сообщение All done.
Далее нужно подождать, и в течение следующих пары секунд запущенные операции закончат свое выполнение.
Здесь важно понимать, что часть кода запускается синхронно, хоть мы используем асинхронность.
Следующий пример - это класс Mutex, он достаточно объемный. Обсудим только его использование.
Итого, Method2 будет выполняться 1 секунду. И после этого мы получим сообщение All done.
Далее нужно подождать, и в течение следующих пары секунд запущенные операции закончат свое выполнение.
Здесь важно понимать, что часть кода запускается синхронно, хоть мы используем асинхронность.
Следующий пример - это класс Mutex, он достаточно объемный. Обсудим только его использование.

SingleInstanceProvider - это класс, который позволяет запускать программу в единственном экземпляре.
Его работа заключается в следующем. Когда приложение запускается впервые, он ставит Mutex на определенную строку. Если программу не выключать, то, при попытке запустить приложение второй раз, будет произведена проверка на наличие lock для этого Mutex. Если lock есть, то вместо того, чтобы запустить второй экземпляр приложения, у нас возьмутся аргументы и передадутся уже запущенному процессу. Второй раз приложение не запустится. Если вы пишете клиентские программы, то это достаточно полезная вещь.
И третий пример - использование SemaphoreSlim. Он нужен тогда, когда нужно запустить множество асинхронных задач, но не более чем X одновременно.
Его работа заключается в следующем. Когда приложение запускается впервые, он ставит Mutex на определенную строку. Если программу не выключать, то, при попытке запустить приложение второй раз, будет произведена проверка на наличие lock для этого Mutex. Если lock есть, то вместо того, чтобы запустить второй экземпляр приложения, у нас возьмутся аргументы и передадутся уже запущенному процессу. Второй раз приложение не запустится. Если вы пишете клиентские программы, то это достаточно полезная вещь.
И третий пример - использование SemaphoreSlim. Он нужен тогда, когда нужно запустить множество асинхронных задач, но не более чем X одновременно.

Также я здесь ввел Enum ThredLoading для того, чтобы у нас не было кучи непонятных магических чисел при использовании этого метода.
Как он работает? Давайте разберем сначала задачу. У нас есть 10 задач, каждая из которых выполняется так: первая 1 секунду, вторая - 2 секунды, а третья - 3 секунды, и так далее до 10. Нам нужно выполнить все эти задачи так, чтобы у нас одновременно выполнялось не более чем четыре задачи.
Как он работает? Давайте разберем сначала задачу. У нас есть 10 задач, каждая из которых выполняется так: первая 1 секунду, вторая - 2 секунды, а третья - 3 секунды, и так далее до 10. Нам нужно выполнить все эти задачи так, чтобы у нас одновременно выполнялось не более чем четыре задачи.

Итого, мы можем разбить все эти задачи на группы, где первая группа будет 1, 2, 3, 4, вторая 5, 6, 7, 8, и третья 9, 10. Номер задачи соответствует тому, сколько секунд она будут выполняться. И далее мы через Task.WhenAll ожидаем выполнение каждой задачи. Проблема здесь будет в том, что все эти задачи суммарно будут выполняться за 22 секунды, хотя мы можем сделать быстрее, а 22 - это потому что первая группа будет выполняться 4 секунды, вторая группа будет выполняться 8 секунд, третья - 10. Получается 22 секунды.

На изображении видно как будут выполняться эти задачи с использованием SemaphoreSlim. Как только одна из задач закончит работу, то она сообщит о завершении, и будет позволено запустить выполнение следующей задачи. Итого, как только у нас первая задача завершается, у нас ставится 5 задача, и суммарно это все завершится за 18 секунд.
Подведем итоги.
Первый вывод в том, что в современном .NET нет необходимости в использовании Thread'ов. Как я и сказал, Thread'ы уже устарели. В .NET 4.5 появился класс Task, с которым работать гораздо более приятно и удобно, и кода получается сильно меньше, он становится понятнее. Хотя под капотом все равно это в какой-то степени реализация тех же Thread'ов.
Если происходит блокировка потока бесполезной нагрузкой, необходимо использовать асинхронность. Под бесполезной нагрузкой подразумевается те ситуации, когда мы делаем запрос на какой-то сторонний сервис и просто ждем ответа. То есть, например, как сделать запрос на удаленный сервис? У нас есть клиент-серверное приложение. Как делается запрос? Сначала на клиенте подготавливаются данные и формируется сам запрос, это полезная нагрузка. После этого запрос отправляется. Чтобы запрос выполнился, у нас сначала пакет должен дойти от клиента до сервера, на сервере обработаться, и после этого вернуться обратно. Все это время клиентское приложение будет просто ждать, и это как раз-таки бесполезная нагрузка. Эта ситуация, когда у нас какой-то поток может просто зависнуть и ничего полезного не делать. В таком случае нужно всегда использовать асинхронность для того, чтобы потоки не простаивали, будучи заблокированными паузой, потому что количество потоков в системе ограничено.
При использовании многопоточного кода с общими данными всегда нужно думать о правильной синхронизации.
lock лучше всегда ставить на выделенное для этого поле с типом object. И всегда нужно думать о дедлоках. Это действительно большая проблема. Эта проблема не подсвечивается предупреждениями, а также бывает плавающей. Поэтому, если есть какие-то инструменты, которые позволят минимизировать количество дедлоков, всегда стоит ими пользоваться.
Подведем итоги.
Первый вывод в том, что в современном .NET нет необходимости в использовании Thread'ов. Как я и сказал, Thread'ы уже устарели. В .NET 4.5 появился класс Task, с которым работать гораздо более приятно и удобно, и кода получается сильно меньше, он становится понятнее. Хотя под капотом все равно это в какой-то степени реализация тех же Thread'ов.
Если происходит блокировка потока бесполезной нагрузкой, необходимо использовать асинхронность. Под бесполезной нагрузкой подразумевается те ситуации, когда мы делаем запрос на какой-то сторонний сервис и просто ждем ответа. То есть, например, как сделать запрос на удаленный сервис? У нас есть клиент-серверное приложение. Как делается запрос? Сначала на клиенте подготавливаются данные и формируется сам запрос, это полезная нагрузка. После этого запрос отправляется. Чтобы запрос выполнился, у нас сначала пакет должен дойти от клиента до сервера, на сервере обработаться, и после этого вернуться обратно. Все это время клиентское приложение будет просто ждать, и это как раз-таки бесполезная нагрузка. Эта ситуация, когда у нас какой-то поток может просто зависнуть и ничего полезного не делать. В таком случае нужно всегда использовать асинхронность для того, чтобы потоки не простаивали, будучи заблокированными паузой, потому что количество потоков в системе ограничено.
При использовании многопоточного кода с общими данными всегда нужно думать о правильной синхронизации.
lock лучше всегда ставить на выделенное для этого поле с типом object. И всегда нужно думать о дедлоках. Это действительно большая проблема. Эта проблема не подсвечивается предупреждениями, а также бывает плавающей. Поэтому, если есть какие-то инструменты, которые позволят минимизировать количество дедлоков, всегда стоит ими пользоваться.